[Abstract][1]
By abstracting away the complexity of distributed systems, largescale data processing platforms—MapReduce, Hadoop, Spark, Dryad, etc.—have provided developers with simple means for harnessing the power of the cloud. In this paper, we ask whether we can automatically synthesize MapReduce-style distributed programs from input–output examples. Our ultimate goal is to enable end users to specify large-scale data analyses through the simple interface of examples. We thus present a new algorithm and tool for synthesizing programs composed of efficient data-parallel operations that can execute on cloud computing infrastructure. We evaluate our tool on a range of real-world big-data analysis tasks and general computations. Our results demonstrate the efficiency of our approach and the small number of examples it requires to synthesize correct, scalable programs.
The contribution of this paper is try to generate MapReduce program based on the input-and-output examples. And here are some diffculties that authors encountered during the research:
Functional synthesis technique
While the program synthesis faces many challenges in the general area, but when we restrict the problem to the MapReduce template, we find that this will force discovery of inherently parallel implementations of a desired computation.
A more formal expression of the problem is listed below
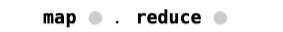
The grey circle signifies the missing pieces of the template. And the dot symbol is reverse function composition.
Dealing with shuffles
Due to the distributed property of the network, an arbitrary permutation of the results of the mapper will be processed by the reducer. To simplify the problem, we are going to limit the synthesis program to the ralm that the order of the intermediate result doesn’t matter.
[Preliminaries][2]
Here is the formal program model and synthesis tasks.
Program
The language used to synthesize programs is a restricted, typed lambda-calculu.
Higher-order sketches (HOS)
This is the same as the functional synthesis technique introduced in the first section. But the wildcard here should be replaced with complete, well-typed and closed program.
Data-parallel components
As defined above, HOS can be any program with wildcards. However, for practival purposes, a HOS will typically be a composition of data-parallel components, such as map and reduce.
Compositional Synthesis Algorithm
To compute a solution of S, the algorithm employs two cooperating phases: synthesis and composition, that act as producers and consumers, respectively.
synthesis phase
Initially, the algorithm attempts to infer the type of terms that may appera for each wildcard in H. This will create a map M from types to sets of programs.
Composition phase
For each HOS h belongs to H, the algorithm attempts to find a map $\mu$, from wildcards to complete programs, such that $\mu h$ is a solution of S. This phase tries to compose a subset of the production to a complete program.
Feedback
Right now, I have got a clear understanding of the MapReduce Program Synthesis, and the basic mechanism.
The section 6 Implementation and Evaluation is left to be read in tomorrow, which includes the implementation detail of the BigLambda project. If everything works well, I can finish the setup task before the class.
Reference
[1] http://pages.cs.wisc.edu/~aws/papers/pldi16.pdf “Paper”
[2] https://liujiacai.net/blog/2014/10/12/lambda-calculus-introduction/#%E7%BC%96%E7%A0%81Boolean(https://liujiacai.net/blog/2014/10/12/lambda-calculus-introduction/#编码Boolean) “lambda-calculus”