Map and Reduce
They are the core functions defined in the functional programming language. The map function takes two parameters, func and para, where the para will be passed to the given func and return the results. Here the para could be a list, in which case every item will be passed once to the given function, and form a list from the return value. While the reduce function is kind of like the filter function.
But the actual action of the map and reduce in the paper is different. MapReduce applies map function to each logical record in input to compute a set of intermediate key/value pairs, and then applies reduce operation to all the values shared by the same key. From the perpective of user, the MapReduce interfaces decouple the operation of the data and the mechanism of distributed computing, and provide users a set of easy-coding interface to interact with data.
Implementation
MapReduce Workflow
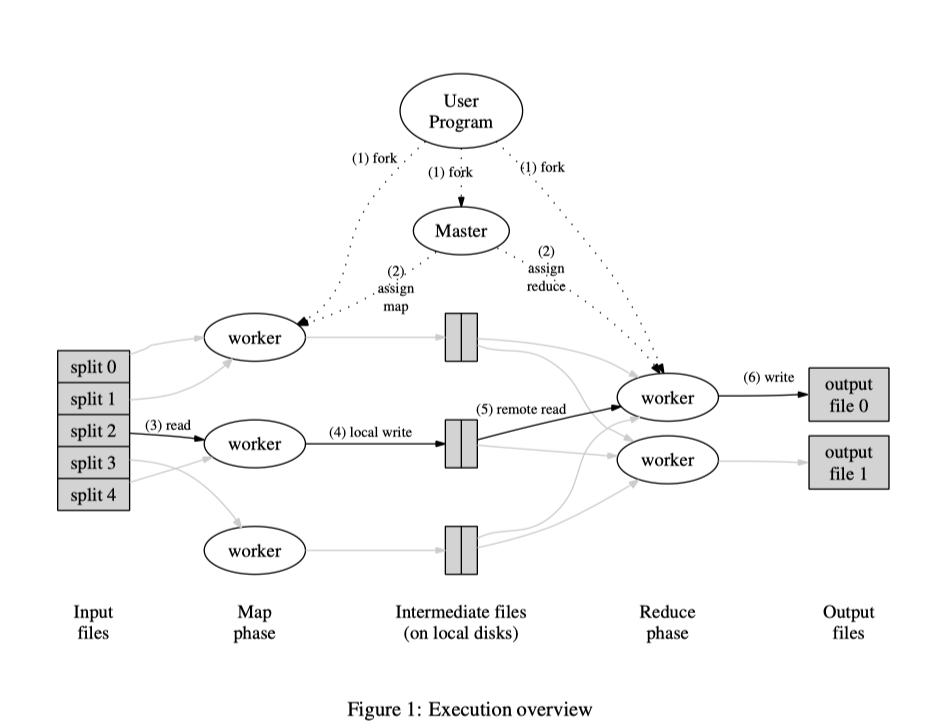
MapReduce will first split the user input into several partitions, and pass them to different machines to execute
maptask. The number of partition (R) and the method of partitioning (hash function) could be specified by the user.And the
mapfunction code is copied to all machines. The partition is formed by the chunks. In general, the size of each chunk is 16MB or 64MB. Denote the number of the chunks as M.One of the copies of the program is the master node, which will search the idle worker nodes and assign them tasks. There are M map tasks and R reduce tasks to assign.
For one map worker, it will first apply the map function to the given input, and buffer the result in memory. Periodically, the buffered pairs are written to local disks, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
When the reduce worker is notified by the master about the locations, it will fetch the buffered data sfrom the local disks of the map workers by remote procedure calls. When it has read all the intermediate data, it will sort it by the intermediate keys.
The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key the the corresponding set of intermediate values to the reduce function. The output of the reduce function is appended to a final output file for this reduce function.
When all map tasks and reduce tasks have been completed, the master wakres up the user program.

Feedback
Feedback on environment setup - 05/19
I have created one basic ubuntu image in Docker and pulled the source code from the Github. But there’s no example to run to test the program. So it seems that I need to create a data set for testing.
Today I finished reading the Paper MapReduce. And I have uploaded my critique.
plan for 05/20: read the paper MapReduce Program Synthesis and try to create the data set
The setup part is expected to be finished in 05/21.