Chord: A Scalable Peer-to-peer Lookup Protocol for Internet Applications
System Model
Support the following features:
- load balance: spreading keys evenly over the nodes
- decentralization: fully distributed; no node is more important than any other
- scalability: the cost of a Chord loopup grows as the log of the number of nodes
- availability: automatically adjusts its internal tables to reflect newly joined nodes as well as node failures
- flexible naming: Chord places no constraints on the structure of the keys it looks up
The Chord Protocol
The consistent hash function assigns each node and key an m-bit identifier using SHA-1 as a base hash function. A node’s identifier is chosen by hashing the node’s IP address, while a key identifier is produced by hashing the key. The identifier length m must be large enough to make the probability of two nodes or keys hashing to the same identifier negligible.
The range of the identifier circle is $2^m$. Key k is assigned to the first node whose identifier is equal to or follows k in the circle.
The lookup algorithm makes use of binary search tech. Every node will store a table with m entries. The $i^{th}$ entry in the table at node n contains the identity of the first node s that succeeds n by at least $2^{i-1}$ on the circle. We denote the $i^{th}$ entry of node n by $n.finger[i]$.
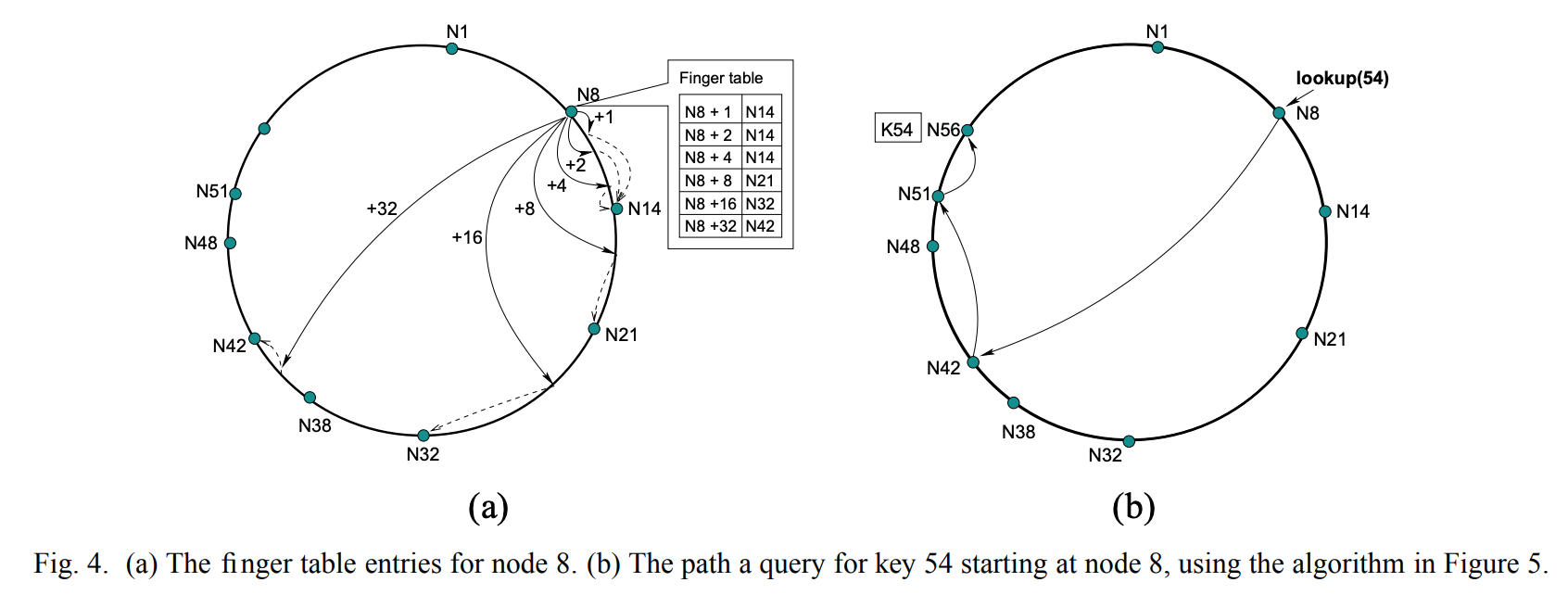
Since from any node, we can reach half of the entire Chord circle, the lookup operation would take O($\log n$) cost.
Impact of node joins on lookups: Sometimes the nodes in the affected region have incorrect successor pointers, or keys may not yet have migrated to newly joined nodes, and the lookup may fail. The higher-layer software using Chord has to notice that the desired data was not found, and has the option of retrying the lookup after a pause.